Recently I came across my old Oculus DK2, my first HMD and although there ware no real games for it, the device made me buy a HTC Vive 🙂
The Oculus Development kit 2 (DK2) was released back in 2014. Long before Facebook even tough about putting its greedy fingers on Oculus, and long before the release of the Oculus rift and the HTC Vive.
The DK2 was ahead of its time with specs relatively close to the later released Oculus Rift and HTC Vive (2016).
| Oculus DK2 | Oculus Rift | HTC VIVE | |
| Resolution | 960×1080 per eye 1920×1080 total | 1080×1200 per eye 2160 x 1200 total | 1080×1200 per eye 2160 x 1200 total |
| Display Type | OLED | OLED | AMOLED |
| Refresh rate | 75Hz | 90Hz | 90Hz |
| Room scale | No | Yes | Yes |
| Controllers | No | Yes | Yes |
Although the DK2 lacks room scale and controller support it can still be very useful for simulation type content such as Space/flight sims and race sims. in my case i wanted to try Elite dangerous on it because my “normal” Vive setup is not ideal for playing siting games.
Although the DK2 is no longer supported officially, it still works with the regular Oculus software, there are however a number of “problems” because the DK2 does not support controllers
Lets start with downloading the Oculus software from there site: https://www.oculus.com/setup/. we need the version for the original Rift which is located at the bottom of the page.
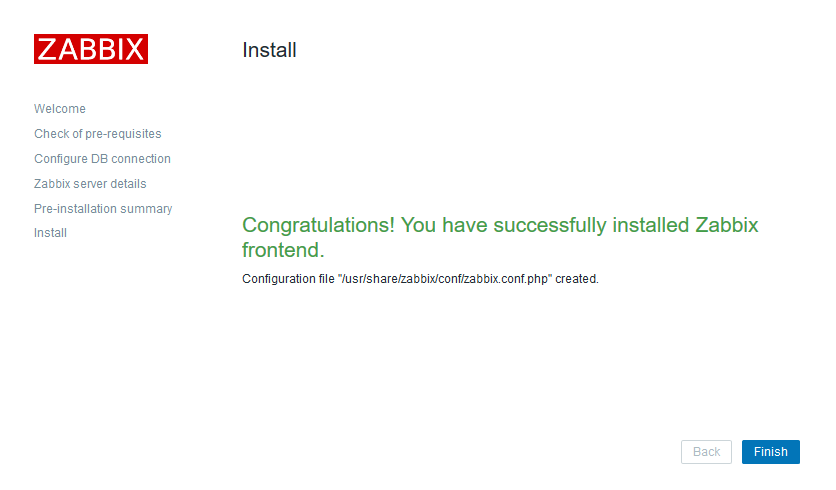
During the installation the installer will download around 6 GB of data (it looks like a lot, but steam VR is also around 6GB). I won’t show the installation (you can only click next anyway).
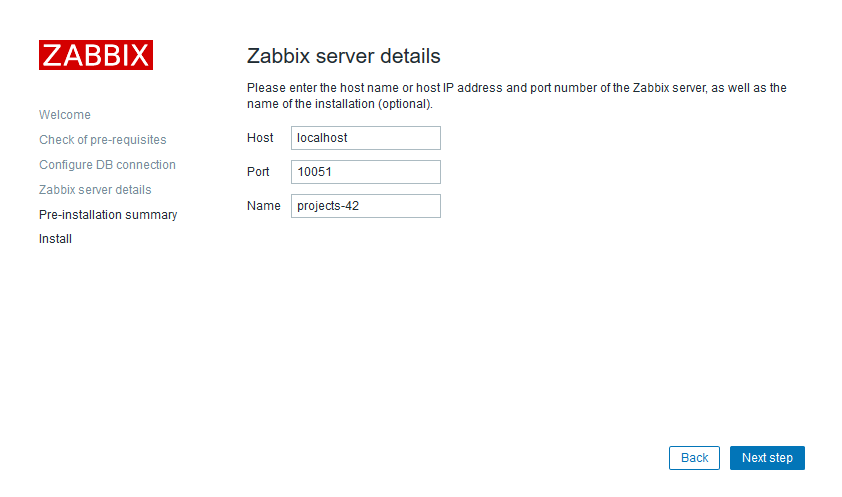
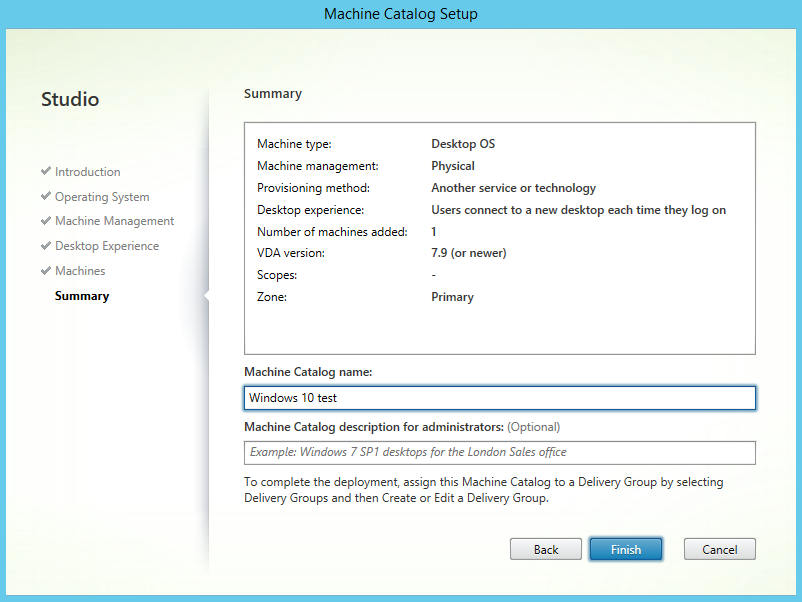
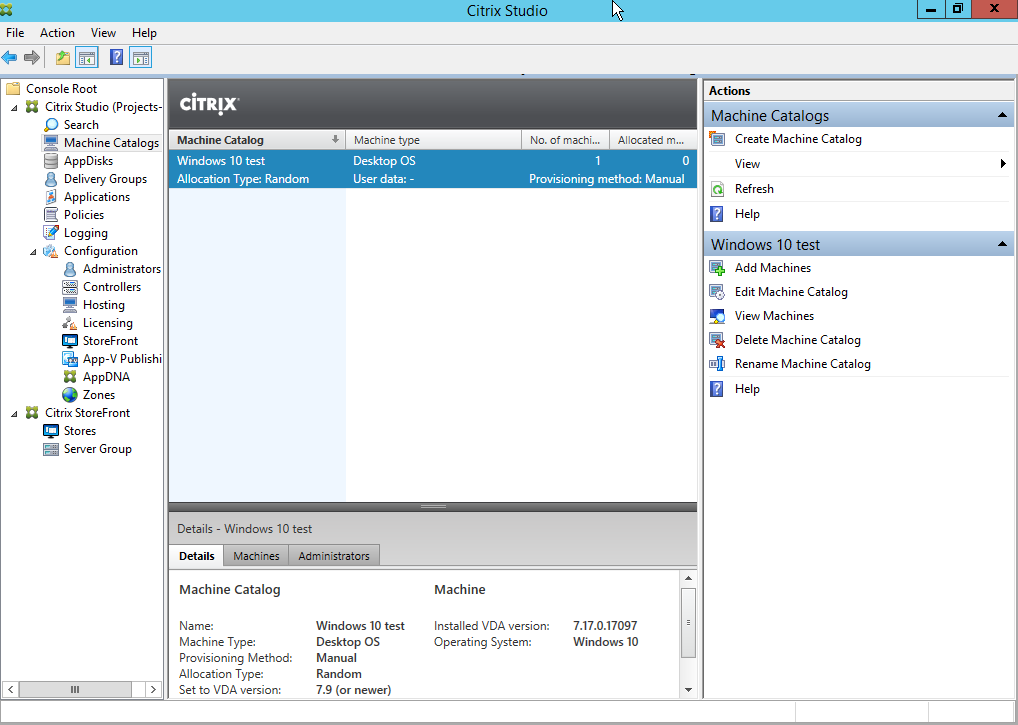
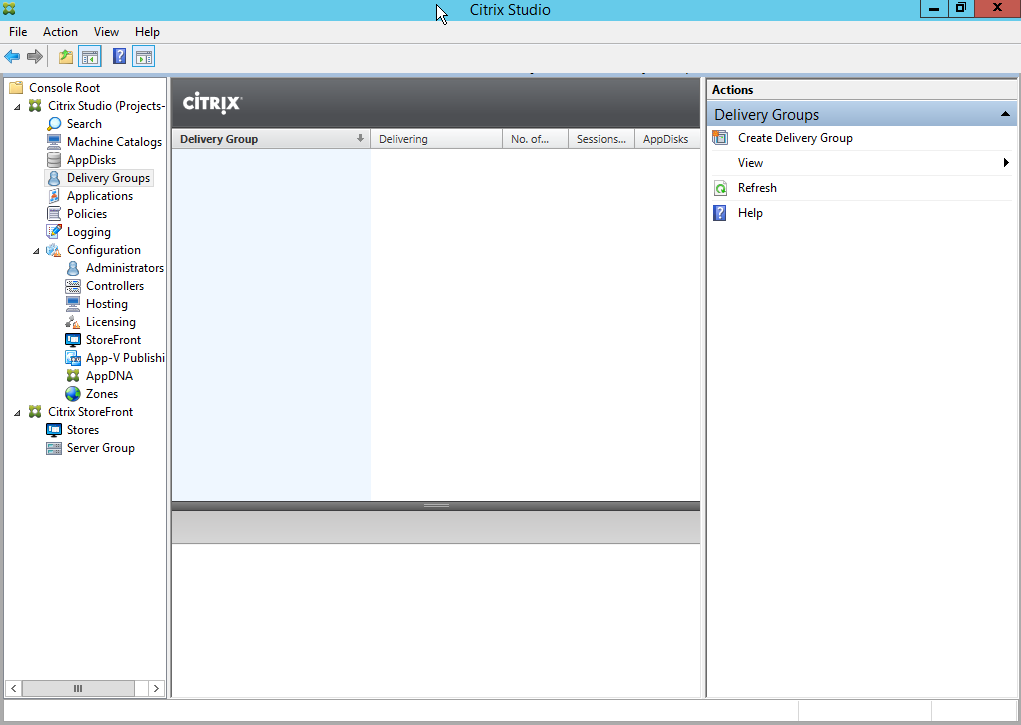
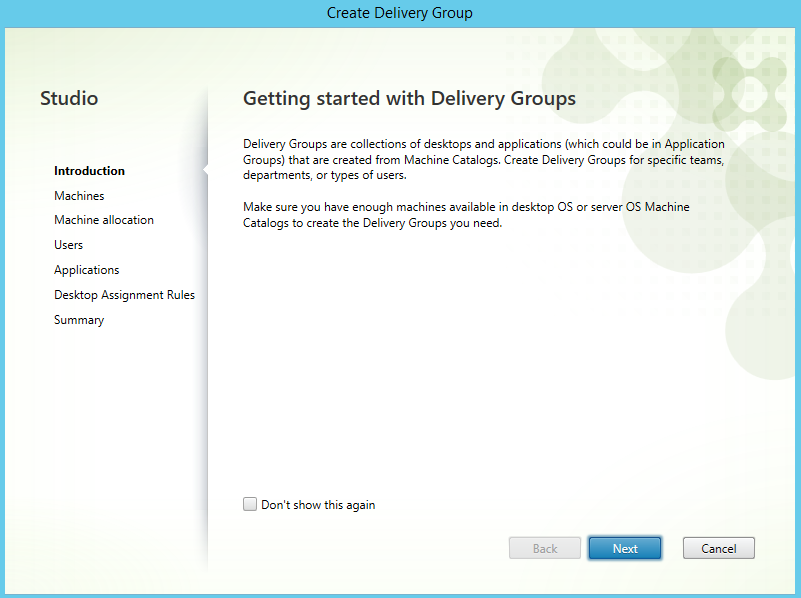
After the installation is complete you will have to configure the application:
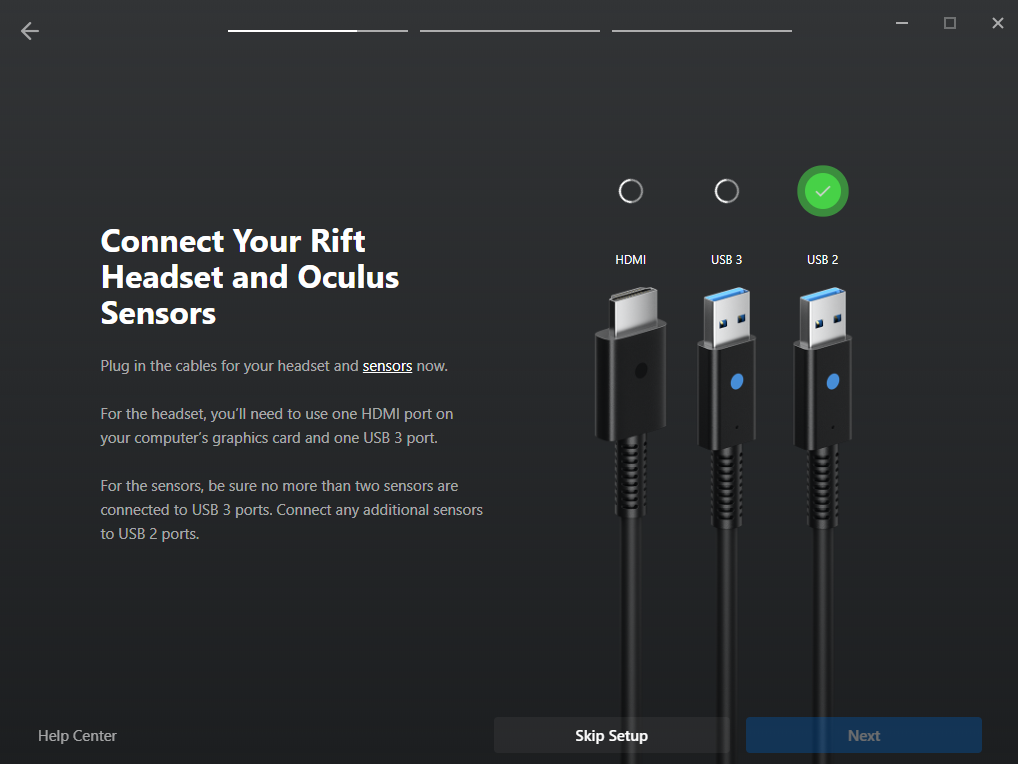
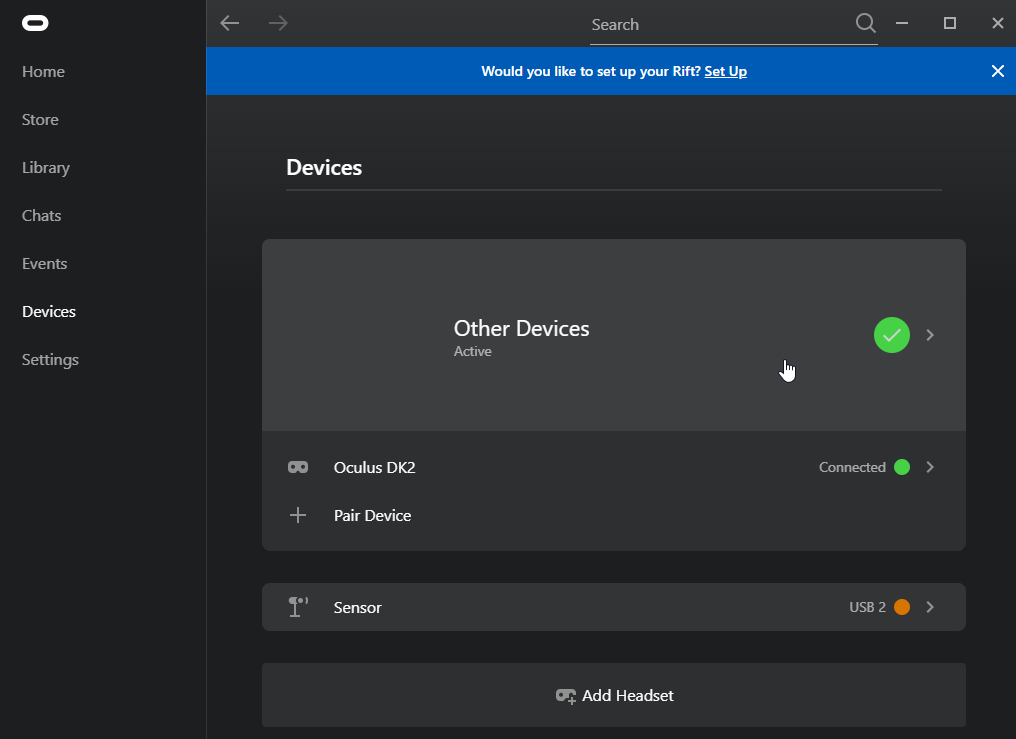
Nice, the DK2 is detected and should work (display image and track movement). But we are not there yet, we have a big “health and safety” notice in the middle of the screen. And we won’t be able to display SteamVR games on the DK2 because the Oculus application disables this by default (Thanks Facebook).
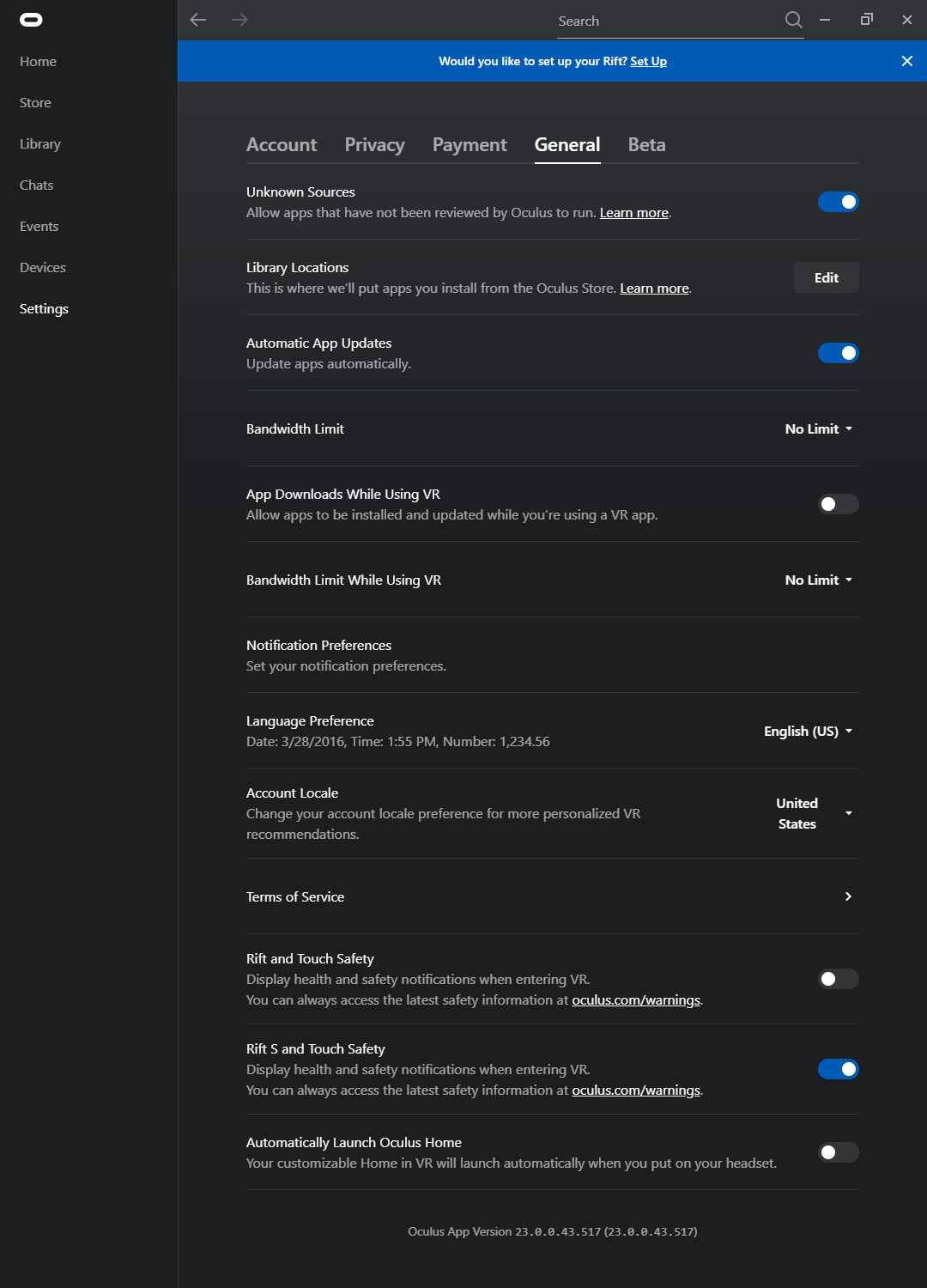
Navigate to the “settings” tab (on the left side of the screen) and select the “General” tab at the top of the screen.
Now Enable the notice after “Allow Unknown Sources” (SteamVR).
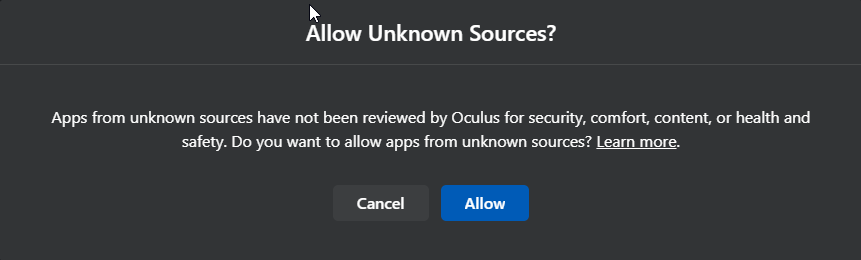
Next up is the big “health and safety” notice. disable the switch after “Rift and Touch Safety”.
Running Games 🙂
To run a Steam game on the DK2 you will need to start the applications in the correct order (otherwise it will not be outputted to the DK2.
- Start the Oculus software, and wait until the DK2 turns on and display’s output;
- Start SteamVR and wait until the DK2 shows the SteamVR output;
- Start the Game;
- Have fun playing games 🙂
I hope this was helpful if you find yourself with a DK2.
Featured image from extremeTech