I remember when I booted Windows Vista for the first time, there where three things that stood out at the time:
- Actual working 64 bit support, which was useful for virtualization (yes, i know about XP x64. And no, it does not count).
- The new color scheme. lets face it, it was quite refreshing after years of blue and green (or gray for the classic users).
- The start menu search bar. At long last i could drop my 20+ layer start menu folder structure, just type the program you need and it will appear.
Over time I realized how much the start menu search bar improved the experience of working with windows vista as a day to day OS. At Microsoft HQ they must have also realized this, because the start menu search bar still existed in Windows 7.
Then windows 10 came out (I skipped the windows 8 and 8.1 disaster). Unfortunately Microsoft figured it was a good idea to use the start menu search to search the entire user profile including: documents, downloads, email, and much more. This meant it was now possible to search for a program, and have the installer for this program listed before the program itself (and this happens quite often). It also introduced some weird behavior where the first three letters of a program will give a hit, but the first four letters wont give the same hit. And in a lot of cases programs would not show up at all.
Fortunately we can fix most of the problems by limiting the indexing for the start search bar to only the start menu.
But first we need to make sure all hidden files and folders are viable in windows Explorer.
In a windows Explorer windows click the “view” tab -> “options” -> “view” tab. You should now see the window from image1 (below)
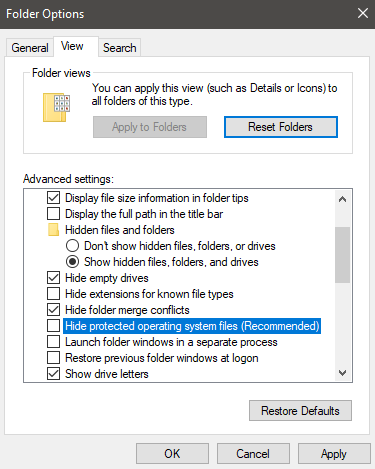
Make sure the “Hide protected operating system files (Recommended)” is NOT checked, and “Show hidden files, folders and drives” is selected.
Next up, open the indexing options by typing “indexing options” in the start menu search bar (and hope it works) image2 should now appear.
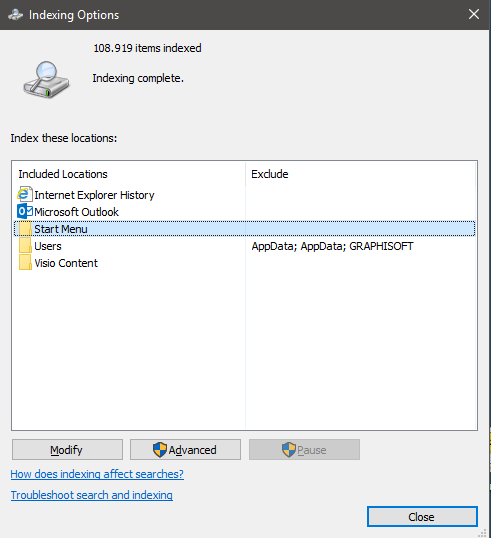
As you can see, there are a lot of non start menu related folders, and the entire users folder is in the index. To change this, click the “Modify” button.
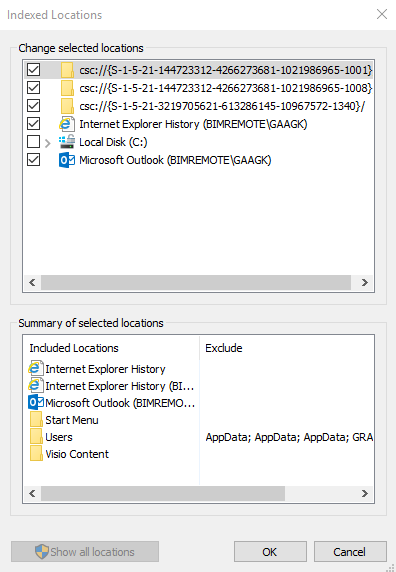
Now deselect all unwanted folders (if you click on a folder/item in the bottom half of the screen (image3) it will auto navigate to the fonder in the top half) and use the top part of the windows (image3) to browse to the 2 start locations.
One is located in “C:\ProgramData\Microsoft\Windows\Start Menu”, the other one is located in “C:\Users\<yourUserName>\AppData\Roaming\Microsoft\Windows\Start Menu”.
Check the boxes before both the start menu locations and click “OK”.
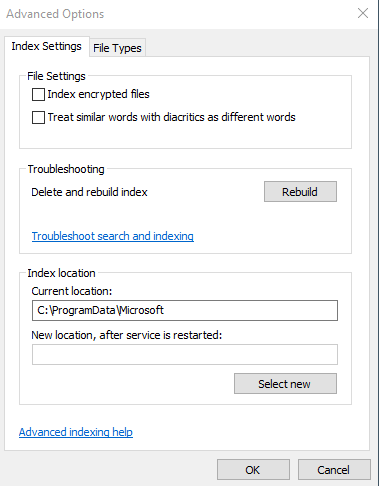
Next click on “Advanced” -> “Rebuild” -> “OK” (image4).
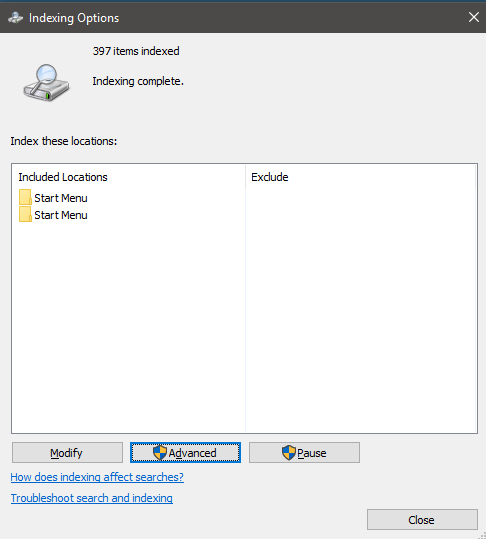
As you can see, there are only two folders left in the index overview, and the number of indexed items has dropped to a more reasonable amount.
The start menu search bar will now function almost like in Windows vista and 7. And it will find the program your looking for 🙂